21st October 2016 AI milestone: a new system can match humans in conversational speech recognition A new automated system that can achieve parity and even beat humans in conversational speech recognition has been announced by researchers at Microsoft.
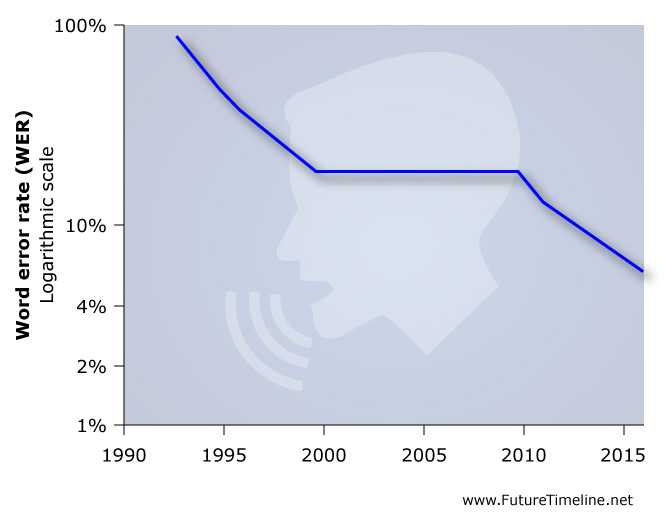
A team at Microsoft's Artificial Intelligence and Research group has published a study in which they demonstrate a technology that recognises spoken words in a conversation as well as a real person does. Last month, the same team achieved a word error rate (WER) of 6.3%. In their new paper this week, they report a WER of just 5.9%, which is equal to that of professional transcriptionists and is the lowest ever recorded against the industry standard Switchboard speech recognition task. “We’ve reached human parity,” said Xuedong Huang, the company’s chief speech scientist. “This is an historic achievement.” “Even five years ago, I wouldn’t have thought we could have achieved this,” said Harry Shum, the group's executive vice president. “I just wouldn’t have thought it would be possible.” Microsoft has been involved in speech recognition and speech synthesis research for many years. The company developed Speech API in 1994 and later introduced speech recognition technology in Office XP and Office 2003, as well as Internet Explorer. However, the word error rates for these applications were much higher back then.
In their new paper, the researchers write: "the key to our system's performance is the systematic use of convolutional and LSTM neural networks, combined with a novel spatial smoothing method and lattice-free MMI acoustic training." The team used Microsoft’s own Computational Network Toolkit – an open source, deep learning framework. This was able to process deep learning algorithms across multiple computers, running a specialised GPU to greatly improve its speed and enhance the quality of research. The team believes their milestone will have broad implications for both consumer and business products, including entertainment devices like the Xbox, accessibility tools such as instant speech-to-text transcription, and personal digital assistants such as Cortana. “This will make Cortana more powerful, making a truly intelligent assistant possible,” Shum said. “The next frontier is to move from recognition to understanding,” said Geoffrey Zweig, who manages the Speech & Dialog research group. Future improvements may also include speech recognition that works well in more real-life settings – places with lots of background noise, for example, such as at a party or while driving on the highway. The technology will also become better at assigning names to individual speakers when multiple people are talking, as well as working with a wide variety of voices, regardless of age, accent or ability. The full study – Achieving Human Parity in Conversational Speech Recognition – is available at: https://arxiv.org/abs/1610.05256 ---
Comments »
|